A Plain-English Guide to Understanding Scientific Research
You’ve seen the headlines: “Study Links Coffee to Longer Life” or “New Research Suggests Red Wine Prevents Heart Disease.” A week later, a contradictory headline appears. How can science keep flip-flopping? The answer, more often than not, isn’t that the science is broken; it’s that not all studies are built the same. Understanding the different types of scientific research is one of the most useful thinking tools you can develop. Let’s break it down.
The Gold Standard: The Randomized Controlled Trial (RCT)
If scientific studies were currencies, the randomized controlled trial (RCT) would be gold bullion. Here’s how it works: researchers take a group of participants and randomly assign them to either receive a treatment (the experimental group) or not (the control group). Random assignment is the magic ingredient; it helps ensure the two groups are as similar as possible, so any difference in outcomes can be attributed to the treatment itself.
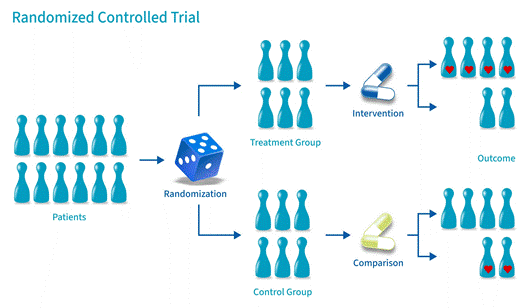
What it’s great at: Establishing causation — not just that two things are correlated, but that one actually causes the other. If a new drug reduces blood pressure in an RCT, you can be fairly confident the drug is doing the work.
What it’s not great at: RCTs are expensive, time-consuming, and sometimes ethically impossible. You can’t randomly assign people to smoke cigarettes for 20 years to study lung cancer. They’re also often conducted on narrow populations that may not represent everyone.
Blinding the Study: Single, Double, and Triple-Blind Trials
Even in a well-designed RCT, human psychology can sneak in and distort results. That’s where blinding comes in.
In a single-blind study, participants don’t know which group they’re in — they don’t know if they’re getting the real treatment or a placebo. This helps prevent the placebo effect, where simply believing you’re receiving treatment can make you feel better.
In a double-blind study, neither the participants nor the researchers know who is in which group. This is considered the most rigorous standard for clinical trials. Some studies go even further with triple-blinding, where even the statisticians analyzing the data don’t know which group is which until the analysis is complete.
What it’s great at: Minimizing bias from both participants and researchers — some of the most insidious sources of error in science.
What it’s not great at: Blinding isn’t always possible. You can’t blind someone to whether they received surgery or not, or whether they changed their diet. Even double-blind trials can be “unblinded” if a drug has obvious side effects that reveal who’s in the treatment group.
Prospective Studies: Following People Forward in Time
A prospective study starts before the outcome of interest has occurred and follows participants forward in time to see what happens. Researchers identify a group (called a cohort), collect baseline information, and then track them over months or years.
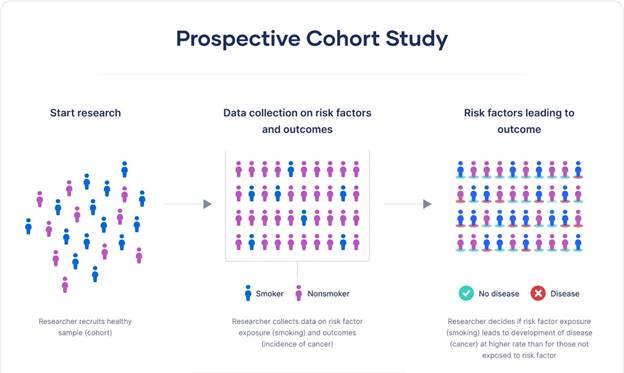
The famous Nurses’ Health Study, launched in 1976, is a classic example. Researchers enrolled over 120,000 nurses and tracked their health behaviors and outcomes for decades. This kind of long-term follow-up has produced enormous insights into diet, lifestyle, and disease.
What it’s great at: Studying how exposures like diet or exercise relate to health outcomes. Because data is collected as events unfold, recall bias — the tendency to misremember past events — is reduced.
What it’s not great at: They’re expensive and slow. If you want to study a disease that takes 20 years to develop, you might wait 20 years for answers. They also can’t prove causation the way RCTs can, because participants aren’t randomly assigned to their exposures.
Retrospective Studies: Looking Backward
A retrospective study does the opposite — it starts with an outcome that has already occurred and looks backward to identify possible causes or risk factors. Researchers might study a group of people who already have a disease and compare their past exposures to a group without the disease.
What it’s great at: Speed and cost. Since you’re working with existing data or records, you can complete a study in months rather than decades. Particularly useful for rare diseases, where waiting for prospective cases would take too long.
What it’s not great at: Prone to recall bias — people remember their past differently depending on their current health. A person who developed cancer may scrutinize their past habits very differently than a healthy person.

Case -Control Studies: Comparing Cases to Controls
A case-control study is a type of retrospective study that specifically compares people with a condition (cases) to people without it (controls), looking backward to compare their exposures. It’s particularly useful for rare diseases — rather than enrolling tens of thousands and waiting, you find 100 people who already have the condition, match them to 100 similar people who don’t, and compare their histories.
What it’s great at: Efficiency when studying rare conditions or diseases with long latency periods.
What it’s not great at: Selecting the right control group is tricky and can introduce bias. They also share the retrospective study’s weakness of recall bias.

Cross-Sectional Studies: A Snapshot in Time
A cross-sectional study is like a photograph — it captures data from a population at a single point in time. National health surveys, for example, might ask thousands of people about their diet, exercise, and health status simultaneously.
What it’s great at: Efficiently describing the prevalence of conditions or behaviors across a population. Excellent for public health planning.
What it’s not great at: Because everything is measured at one moment, you can’t determine whether the exposure came before or after the outcome. Does depression cause physical inactivity, or does physical inactivity cause depression? A cross-sectional study can’t tell you.
Observational vs. Experimental Studies: The Big Divide
It’s worth stepping back to note the most fundamental distinction in research: observational versus experimental studies.
In observational studies (like prospective, retrospective, and cross-sectional studies), researchers observe people as they live their lives without intervening. They can find associations and correlations, but proving causation is always more difficult.
In experimental studies (like RCTs), researchers actually do something — they assign treatments, change variables, and measure what happens. This is why RCTs are so valued: intervention + randomization = the best shot at establishing cause and effect.

Meta-Analyses and Systematic Reviews: The View from 30,000 Feet
What happens when you have dozens of individual studies on the same question and they don’t all agree? Enter the systematic review and its statistical cousin, the meta-analysis.
A systematic review is a rigorous, exhaustive summary of all the available research on a specific question. Researchers search databases methodically, apply strict inclusion criteria, and synthesize what the evidence shows as a whole.
A meta-analysis goes one step further: it statistically combines the data from multiple studies to produce a single, pooled estimate. This dramatically increases the effective sample size and statistical power.
What they’re great at: Giving you the big picture. A single study might show a drug works; a meta-analysis of twenty studies gives you much greater confidence — or might reveal that the positive results were an anomaly.
What they’re not great at: “Garbage in, garbage out.” If the underlying studies are flawed, combining them doesn’t fix those flaws — it might just obscure them. Meta-analyses can also be manipulated by cherry-picking which studies to include.

Peer Review: The Gatekeeper (With Flaws)
You’ve probably heard the term peer-reviewed study used as a badge of credibility. Peer review means that before a study is published in a scientific journal, it is evaluated by independent experts in the same field who assess its methodology, analysis, and conclusions. It’s a critical quality-control mechanism.
What it’s great at: Catching obvious errors, methodological problems, and unsupported conclusions before they reach the public.
What it’s not great at: Peer review is not infallible. Reviewers are human, biased, and usually unpaid volunteers working with limited time. High-profile journals have published studies that were later retracted. Peer review filters out the worst work, but it doesn’t guarantee truth.
Putting It All Together
The next time you read about a new study, ask a few key questions: Was it observational or experimental? How many people were involved? Was it peer-reviewed? Has it been replicated? A single observational study showing a correlation between two things is interesting — but it’s just a starting point. Confidence builds when multiple types of studies, done by different research teams, in different populations, point in the same direction.
Science isn’t a collection of facts — it’s a process of accumulating evidence. Knowing how that process works makes you a far better reader of it.

Leave a comment